
Use After Free
仅供个人学习参考
原理
简单的说,Use After Free 就是其字面所表达的意思,当一个内存块被释放之后再次被使用。但是其实这里有以下几种情况
内存块被释放后,其对应的指针被设置为 NULL , 然后再次使用,自然程序会崩溃。
内存块被释放后,其对应的指针没有被设置为 NULL ,然后在它下一次被使用之前,没有代码对这块内存块进行修改,那么程序很有可能可以正常运转。
内存块被释放后,其对应的指针没有被设置为 NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能会出现奇怪的问题。
而我们一般所指的 Use After Free 漏洞主要是后两种。此外,我们一般称被释放后没有被设置为 NULL 的内存指针为 dangling pointer。
例题
HITCON-training 中的 lab 10 hacknote
https://raw.githubusercontent.com/GNchen1/Pages/main/Img/hacknote
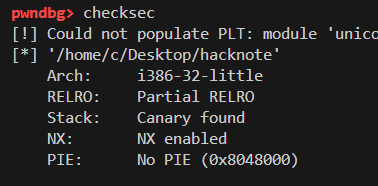
在delete函数中发现有uaf漏洞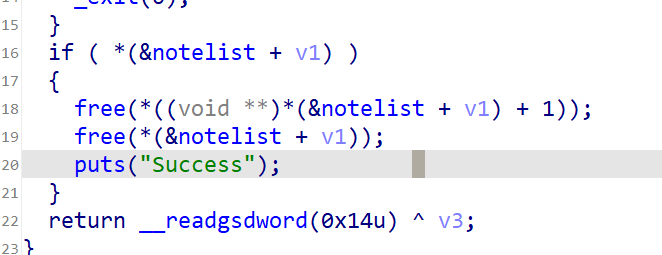
magic函数可以获取flag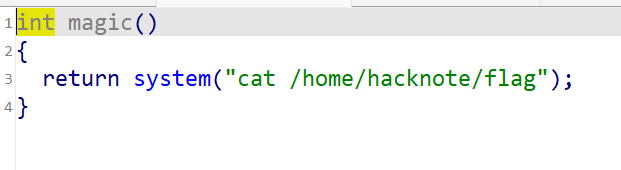
结合add_note函数和print_note函数可以发现print content的方式

即去调用这个¬elist + v1 处的内容(把这个地方当成一个函数来用),正常情况下是会调用print_note_content函数(即下图)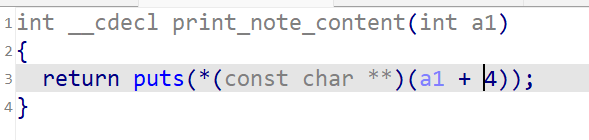
思路是修改note的print_note_content函数为magic函数,从而在执行print_note的时候执行magic,我们唯一能写入的方式是写入content
进入gdb调试
首先创建两个note
然后查看heap和bin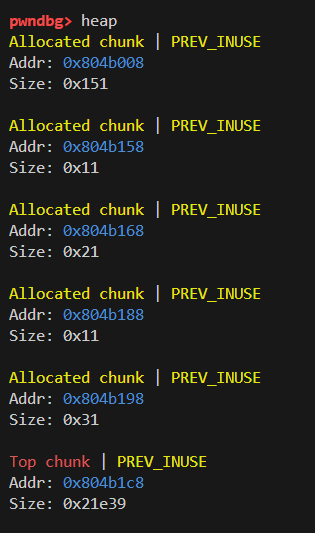
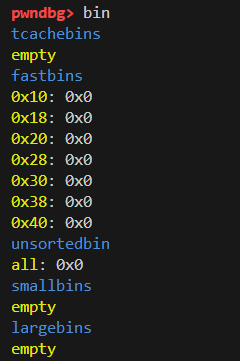
bin是空的,heap发现有多个chunk段,用x命令查看对应内容,从第二个(0x804b158)开始看可以看到刚刚创建的两个note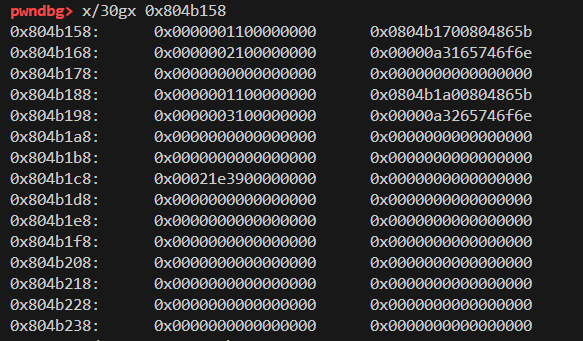
可以看到note0_content的地址0x0804b170 然后后面的0x0804865b内容如下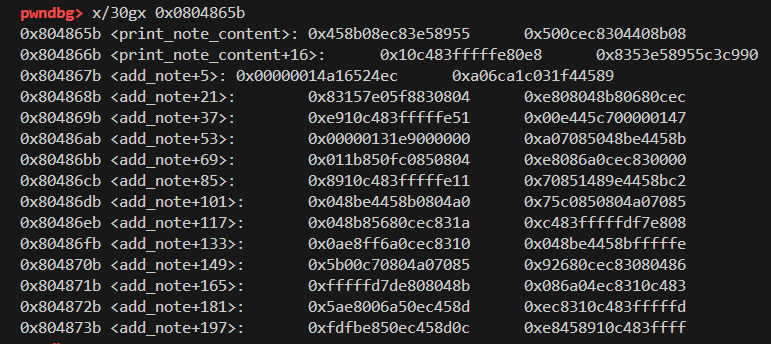
在ida里面看是这个函数
是print_note_content函数
那么我们能否修改这个函数呢
此时利用uaf漏洞可以做到
我们先free掉上面的两个note(调用delete函数)
此时的bin是这样的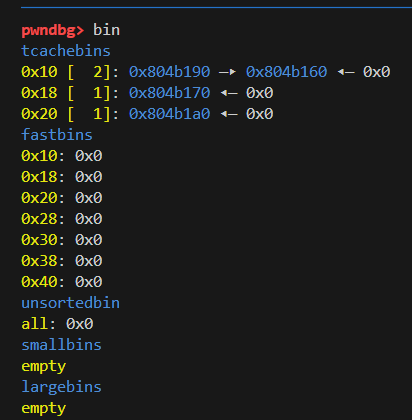
然后我们再创建一个新的note
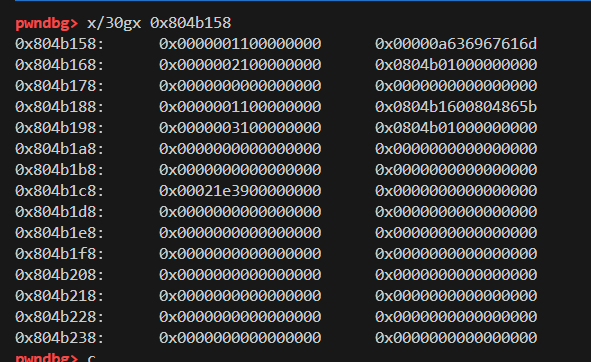
可以看到我们输入的content覆盖了print_note_content函数地址所在的位置
换句话说,我们新创建的note使用了note0这个chunk,并且由于uaf,即对应的指针没有被置为null,所以note0仍可以被正常使用,此时我们再次print note0,就会去调用我们输入的content,也就达到了我们的目的
疑点:为什么我们输入的content会刚好覆盖到print_note_content函数地址所在的位置?
首先补充一下Tcache Bins的相关知识
Tcache Bins
glibc-2.27开始,官方才引入了Tcache Bins结构,然后很不幸的是我的Ubuntu18刚好是glibc-2.27,所以就有了这块内容的补充
概述
Tcache全名为Thread Local Caching,它为每个线程创建一个缓存,里面包含了一些小堆块。无须对arena上锁既可以使用,所以采用这种机制后分配算法有不错的性能提升。每个线程默认使用64个单链表结构的bins,每个bins最多存放7个chunk,64位机器16字节递增,从0x20到0x410,也就是说位于以上大小的chunk释放后都会先行存入到tcache bin中。对于每个tcache bin单链表,它和fast bin一样都是先进后出,而且prev_inuse标记位都不会被清除,所以tcache bin中的chunk不会被合并,即使和Top chunk相邻。
另外tcache机制出现后,每次产生堆都会先产生一个0x250大小的堆块,该堆块位于堆的开头,用于记录64个bins的地址(这些地址指向用户数据部分)以及每个bins中chunk数量。在这个0x250大小的堆块中,前0x40个字节用于记录每个bins中chunk数量,每个字节对应一条tcache bin链的数量,从0x20开始到0x410结束,刚好64条链,然后剩下的每8字节记录一条tcache bin链的开头地址,也是从0x20开始到0x410结束。还有一点值得注意的是,tcache bin中的fd指针是指向malloc返回的地址,也就是用户数据部分,而不是像fast bin单链表那样fd指针指向chunk头。
在有了tcache机制后,无论分配还是释放,操作64位下0x20和0x410大小的chunk,tcache都是首当其冲,直到达到其每种bin的上限7为止。还有一种情况就是fast bin或者small bin返回了一个堆块,且tcache对应大小的bin中未满的话,那么该fast bin或者samll bin链中的堆块会被加入到对应tcache bin中直至其上限。
Tcache 结构
1 | /* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ |
可以看到,每个线程最多只能有64个Tcache Bin,且用单项链表储存free chunk, 每个线程都有一个tcache_perthread_struct结构体
如下为Tcache Bins分配规则: (摘自ctfwiki)
内存释放:
可以看到,在 free 函数的最先处理部分,首先是检查释放块是否页对齐及前后堆块的释放情况,便优先放入 tcache 结构中
内存申请:
在内存分配的 malloc 函数中有多种情况,会将内存块移入 tcache 中:
首先,申请的内存块符合 fastbin 大小时并且在 fastbin 内找到可用的空闲块时,会把该 fastbin 链上的其他内存块放入 tcache 中
其次,申请的内存块符合 smallbin 大小时并且在 smallbin 内找到可用的空闲块时,会把该 smallbin 链上的其他内存块放入 tcache 中
当在 unsorted bin 链上循环处理时,当找到大小合适的链时,并不直接返回,而是先放到 tcache 中,继续处理
tcache 取出:
在内存申请的开始部分,首先会判断申请大小块,并验证 tcache 是否存在,如果存在就直接从 tcache 中摘取,否则再使用_int_malloc 分配 Tcache Bin遵守LIFO(先进后出)
在循环处理 unsorted bin 内存块时,如果达到放入 unsorted bin 块最大数量,会立即返回。不过默认是 0,即不存在上限
在循环处理 unsorted bin 内存块后,如果之前曾放入过 tcache 块,则会取出一个并返回
大抵是像个类似于 fastbin 的单独链表,只是它的 check,并没有 fastbin 那么复杂,仅仅检查 tcache->entries[tc_idx] = e->next;
然后在上面查看bin时就会发现free过后先放入了tcache bins
Tcache Bin遵守LIFO,所以在free掉两个chunk后, tcache中会有两个0x10大小的chunk, 再申请8字节的chunk, 会返回两个chunk, 后一个chunk就是之前的chunk0, 写入magic就会覆盖原chunk0的print_note_content函数的地址, 新生成的note不是chunk0, 而是chunk3, 本题的UAF是指释放chunk0后, 又使用了chunk0
exp
1 | from pwn import * |